Platforms and Algorithms for Big Data Analytics
Abstract:
This is an era of Big Data. The
total digital data in this world is expected to double in less than two years.
Big Data is driving radical changes in traditional data analysis platforms and algorithms.
This
tutorial consists of two parts: (i) Big data
platforms and their characteristics (ii) Large-scale classification and
clustering algorithms.
The
first part will provide an in-depth analysis of different platforms available
for studying and performing big data analytics. It will survey different
hardware platforms available for big data analytics and assesses the advantages
and drawbacks of each of these platforms based on various metrics such as
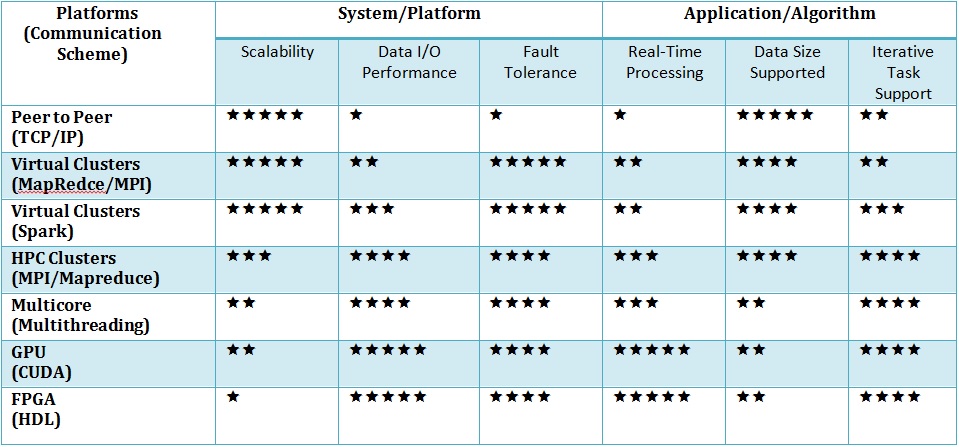
scalability, data I/O rate, fault tolerance, real-time processing, data size
supported and iterative task support. Using a star ratings table, a rigorous
qualitative comparison between different platforms is made for each of the six
characteristics that are critical for the algorithms of big data analytics. In
addition to the hardware, a detailed description of the software frameworks
used within each of these platforms is also discussed along with their
strengths and drawbacks. Some of the critical characteristics that will be
described here can potentially aid the audience in making an informed decision
depending on their computational needs.
The
second part of the tutorial will consist of big data classification and
clustering algorithms. In order to provide more insights into the effectiveness
of each of the platforms in the context of big data analytics, specific
implementation level details of the widely used k-nearest neighbor and the
k-means clustering algorithm on various platforms will be described in the form
of pseudocode. In addition, recent advances in large-scale linear
classification and map-reduce based classification algorithms will also be
discussed. In the context of clustering, some of the well-known one-pass
clustering algorithms and other parallel and distributed clustering solutions
will be briefly mentioned.
Tutorial Presented at the IEEE BigData 2015 Conference: PRESENTATION SLIDES
Source Codes and Installation Instructions
Comparison
of Platforms:
Relevant
References:
1.
Dilpreet Singh and Chandan
K. Reddy, "A survey on platforms for big data analytics",
Journal of Big Data, Vol.2, No.8, pp.1-20, October 2014. (The
first part of the tutorial is primarily based on this survey paper.)
2.
Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, and Ion Stoica. "Spark: cluster computing with working sets", In
Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, pp.
10-10. 2010.
3. Jeffrey Dean, and Sanjay Ghemawat, "MapReduce:simplified data processing on large clusters", Communications of the ACM, Vol. 51, No. 1, pp.107-113, 2008.
4.
John D. Owens, Mike Houston, David Luebke, Simon Green, John E. Stone, and
James C. Phillips, "GPU computing", Proceedings of the
IEEE, vol. 96, no. 5, pp. 879-899, 2008.
5.
Cheng-Tao Chu, Sang Kyun Kim, Yi-An Lin, YuanYuan Yu, Gary R. Bradski, Andrew
Y. Ng, and Kunle Olukotun, "Map-reduce for machine learning on multicore",
In NIPS, pages 281-288, 2006.
6.
Guo-Xun Yuan, C-H. Ho, and Chih-Jen Lin, "Recent advances of large-scale linear classification",
Proceedings of the IEEE, vol. 100, no. 9, pp. 2584-2603, 2012.
7.
Indranil Palit and Chandan K. Reddy, "Scalable and parallel boosting with MapReduce",
IEEE Transactions on Knowledge and Data Engineering (TKDE), vol.24, no.10,
pp.1904-1916, October 2012.
8.
Hanghang Tong and U. Kang, "Big Data Clustering", Book chapter in
Data Clustering: Algorithms and Applications, Charu C. Aggarwal and Chandan K.
Reddy (Eds.), Chapman & Hall/CRC Press, 2013.
Target
Audience:
The target audience is researchers from both academia and industry including graduate students working in the fields of big data, data analytics, data mining and machine learning. In terms of the prerequisites, we expect the audience to be little familiar with some of the basic concepts of data mining such as classification and clustering. Our immediate goal is to provide an overview of the big data platforms and to educate the research community about the platform characteristics and large-scale data mining algorithms. The ultimate goal is to bridge researchers and practitioners to foster interdisciplinary works between the two groups. This tutorial can also attract researchers from the big data industry as it covers many practical aspects of big data analytics. The tutorial will be primarily targeted for researchers who are interested in analyzing large-scale data. They will become knowledgeable about the platforms and algorithms available to perform various kinds of analysis on large-scale data.